Wir alle kennen diese Begriffe – einhergehend mit bekannten Anekdoten, Berichten von „Früher“ und neuen, rein wissenschaftlichen Erkenntnissen.
Man kann sagen, dass wir im 21.Jahrhundert soviel über die Funktionalität der Stimme wissen, wie nie zuvor. Anders als im Hochleistungssport, wo das neue Wissen über funktionale Abläufe die Akteure zu nie geahnten Hochleistungen geführt hat, scheinen Sänger heute nicht unbedingt besser zu singen als früher.
Woher kommt das, und was ist hierbei die Aufgabe der Gesangspädagogik?
Ich halte es für unsere Pflicht, eine Brücke zu schlagen zwischen prä-wissenschaftlichen, rein kinästhetischen Wahrnehmungen und modernen, physiologisch abgesicherten Fakten.
Scott McCoy beschreibt im ‚Journal of Singing‘ (Volume 77, 2, Nov/Dez 2020), warum er 2013 das Buch „Fundamentals of Great Vocal Technique“ von Michael Trimble herausgegeben hat, was gerade nicht auf solider Forschung basiert, sondern auf Beobachtungen einer gewaltigen Phalanx von großartigen Sängern, mit denen dieser auch gearbeitet hat. So Helge Roswaenge, Lauritz Melchior, Richard Tucker, George London und Dame Eva Turner („the definitive Turandot“).
Mc Coy erklärt das so: “ You will find statements in this text that are explicitly anti-sience. As publisher, I find many of these still to be valid. Science cannot teach anyone how to sing. But it can explain why the techniques we use to create beautiful sound are successful. I believe, there is room for both of these pedagogic viewpoints to coexist, each supporting the other.“
Ich will nun diesen Raum einmal öffnen und doch versuchen, eine fundierte Erklärung auf die vielen Fragen, die unter meinen Schülern aufkommen, zu finden.
Gerade wenn ich mit ‚ganz neuen‘ Bildern in den Unterricht komme.
Trimble zitiert Enrico Caruso: „Never sing into the nasal cavity. If the voice is placed in the nose, it indicates that one is singing too far forward, which is against the rule of song.“ (‚The Art of Singing‘ by Enrico Caruso and Luisa Tetrazzini, New York, 1909)
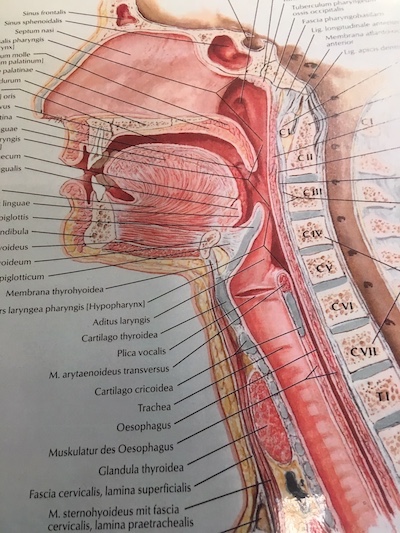
Wir haben doch aber alle gelernt, dass der Nasenschallraum ein Resonator ist, und das der Vordersitz absolut anzustreben ist, um die Tragfähigkeit der Stimme zu sichern…?!
Sind diese Aussagen von 1909 nun überholt („das macht man heute nicht mehr so…!“) und durch exakte Wissenschaft widerlegt?
Anscheinend nicht, denn Johann Sundberg hat Ende des 20. Jahrhunderts bewiesen, dass man nicht ‚in die Maske‘ hineinsingen kann. Hier werden dann nämlich Ursache und Wirkung verwechselt.
Woher kommt denn dann eigentlich die Idee, dass die Stimme ‚vorne‘ sitzen muss, einhergehend mit den Übungen ma/me/mi/mo/mu etc., die diesen Raum stimulieren?
Stephen F. Austin beschreibt in seinem Artikel „Nasal Resonance – Fact or Fiction?“
(Journal of Singing,Vol 57,2, Nov 2000) wie Curtis (1901) mit der Idee, dass die nasale Resonanz die Spannung von den Stimmbändern nimmt, dem berühmtesten Tenor seiner Zeit – Jean de Reske – helfen konnte, dessen angeschlagene Stimme zu kurieren.
De Reske äußerte sich sehr positiv über die Zusammenarbeit, und damit wurden stimmbildnerische Tatsachen geschaffen.
Nun war Curtis aber kein Gesangslehrer, sondern Arzt. D.h., er konnte offensichtlich nicht überschauen was sein – für eine individuelle Stimme hilfreiches – medizinisches Manöver für Auswirkungen auf die Resonantstrategien großer Bühnenstimmen hat.
Austin, der in vielen Artikeln eine sehr hilfreiche Analyse vieler Gesangsschulen der vergangenen 300 Jahre veröffentlicht hat, beschreibt, dass die Arbeit mit nasalen Silben (ma/me/mi/mo/mu) vor den Veröffentlichungen von Curtis keine Relevanz hatte.
Es ist also ein Phänomen des 20. Jahrhunderts!
In einer Formantenalalyse zeigt er sehr deutlich, das bei Tönen mit geschlossenem Nasenschallraum (Steuerung über das Gaumensegel) F1 bei 800Hz, F2 bei ca 1150Hz und F3 bei über 2600Hz deutliche Erhöhungen erkennbar sind.
Wird der Nasenschallraum dagegen offen gelassen, gibt es einen deutlichen Einbruch bei F1, während bei F3 ein echtes „frequency zero“ eintritt, d.h., gerade da, wo der Sängerformant (bei 2600-3200Hz) eintreten sollte, wirkt die gewählte Resonanzstrategie eher als ‚Schalldämpfer‘ und beeinträchtigt so die Tragfähigkeit der Stimme im großen Raum.
Woran liegt es jetzt, dass wir an diesen Strategien so festhalten, wenn sie doch offensichtlich kontraproduktiv sind?!
Einerseits wohl an dem vertrauten Bild, dass „alles“ offen sein muss, um einen professsionellen Klang zu erreichen.
Andererseits brauchen wir die deutliche kinästhetische Wahrnehmung, die der offene Nasenschallraum mit sich bringt. (Kopfresonanz = gut!!)
Die Schlussfolgerungen, die daraus gezogen werden, führen nur zu oft in die falsche Richtung.
Als Sänger und Lehrer müssen wir die Wahrnehmung von Nasalität und einem versiegelten Nasenschallraum unterscheiden lernen. Denn nur Letzteres führt, verbunden mit einer offenen Kehle, zum ‚Maskenklang‘ – und der sitzt höher als die Nase.
Übungen dafür sind also niemals mit nasalen Silben (mo/ma) verbunden, sondern immer mit Explosivlauten b/p/t/k/ oder Frikativen wie f/s/v/z.
Kombiniere ich diese Laute mit Vokalen, hebt sich das Gaumensegel und versiegelt den Nasenschallraum. Das macht die Stimme tragfähig im großen Raum, weil sie so reich an Obertönen ist.
Michael Trimble berichtet, dass Leonard Warren, einer der großen dramatischen Baritone, von seinen Schülern als „Dschinn“-wie ein Flaschengeist- bezeichnet wurde, weil er immer auf der Hinterbühne der Met mit ‚Bobobobobob‘ zu hören war:
Aktivierung der echten Kopfresonanz mit kleinsten Übungen, diese Wahrnehmung gilt es dann beim voll ausgesungenen Klang aufrecht zu erhalten.